
Crack (Road) Image Segmentation
Introduction
Road crack detection is an essential task in infrastructure maintenance, ensuring road safety and timely repair of deteriorating surfaces. Automatic detection of cracks in road images poses significant challenges due to complex backgrounds, uneven illumination, irregular crack patterns, and the presence of noise. Traditional deep learning models like ResNet have made progress in this domain, but limitations such as pooling-induced information loss and the difficulty of capturing fine-grained details have led to a demand for more sophisticated approaches.
This project aims to address these limitations by proposing a novel model, Wavelet U-Net (WUNet), that replaces conventional pooling layers with Discrete Wavelet Transformation (DWT) and integrates a self-attention mechanism to capture both local and global contextual information. The model demonstrated a substantial improvement in performance, achieving a 0.4 increase in F1-score compared to a baseline ResNet model.
Background and Motivation
Image classification and segmentation tasks have a rich history, beginning with early edge detection methods and evolving into modern deep learning techniques. The introduction of Convolutional Neural Networks (CNNs) revolutionized image classification by learning hierarchical feature representations through layers of convolution and pooling operations. However, in tasks like road crack detection, traditional CNNs often struggle due to the irregular and small-scale nature of cracks, noise interference, and the inherent loss of information during max-pooling operations.
Segmentation architectures such as U-Net introduced the concept of skip connections between the encoder and decoder, allowing for better feature preservation and improved segmentation of smaller classes. While U-Net addresses some challenges, max pooling in these architectures can still result in the loss of important features, particularly in high-noise environments like road crack images.
The motivation for this project is to further enhance the performance of crack detection models by addressing two key issues: (1) minimizing information loss during downsampling, and (2) improving the model’s ability to capture fine details and contextual information.
Related Work
Convolutional Neural Networks (CNNs):
CNNs are widely used for image classification and segmentation tasks. Early CNN-based models used handcrafted filters, but more advanced architectures now learn complex features automatically. Despite their success, CNNs suffer from information loss due to pooling layers, which can hinder performance when detecting small-scale patterns like road cracks.U-Net Architecture:
U-Net has become a popular choice for image segmentation tasks, particularly in medical imaging and tasks with imbalanced datasets. Its skip connections allow for direct information flow from the encoder to the decoder, improving segmentation of smaller classes and reducing the risk of overfitting. However, U-Net still relies on max pooling, leading to irreversible losses of detail, which is critical for tasks like crack detection.
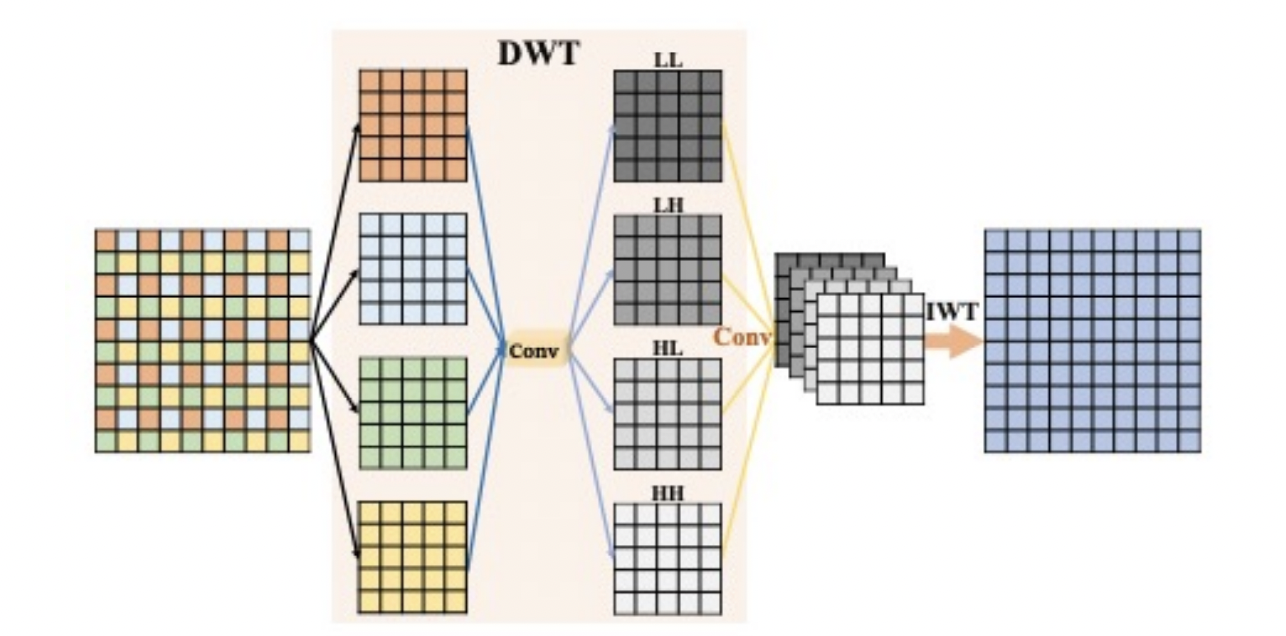
- Wavelet Transform in Deep Learning:
Wavelet transforms are powerful tools for preserving both frequency and spatial information. Wavelet U-Net (WUNet) integrates wavelet transforms into the U-Net architecture, replacing max-pooling with DWT to maintain higher levels of detail during downsampling. The inverse wavelet transform (IWT) restores resolution during upsampling, ensuring no loss of information between layers.
Proposed Methodology
- Model Architecture The proposed Wavelet U-Net (WUNet) consists of an encoder-decoder structure, similar to traditional U-Net, but with several key differences:
- Discrete Wavelet Transform (DWT) is used in place of max-pooling in the encoder. This allows for the preservation of both frequency and spatial information during downsampling, reducing the loss of critical texture information.
- Inverse Wavelet Transform (IWT) is applied in the decoder to reconstruct high-resolution feature maps, ensuring no information is lost during upsampling.
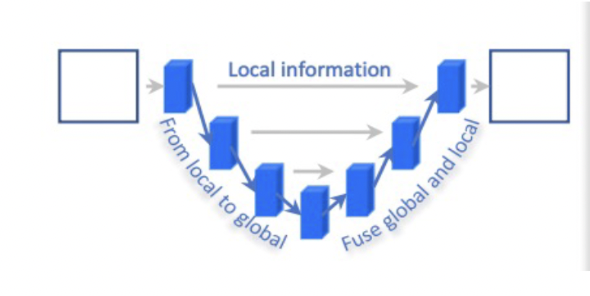
- A self-attention mechanism is incorporated into the model to capture global contextual information, improving the model’s ability to detect cracks in complex and noisy environments.
Discrete Wavelet Transform (DWT) DWT decomposes the input feature maps into four components: approximation, horizontal, vertical, and diagonal details. By retaining the approximation coefficients and discarding the others, the model achieves downsampling without losing important texture information. This is particularly beneficial for detecting small cracks and subtle patterns in the road surface.
Inverse Wavelet Transform (IWT) IWT restores the high-resolution feature maps in the decoder by inverting the DWT operation. This ensures that no information is lost during the upsampling process, preserving the fine details necessary for accurate crack detection.
- Self-Attention Mechanism The self-attention mechanism allows the model to weigh the importance of different regions in the image, improving its ability to capture long-range dependencies and contextual information. This is crucial for road crack detection, where cracks can vary in size, orientation, and appearance across different images.
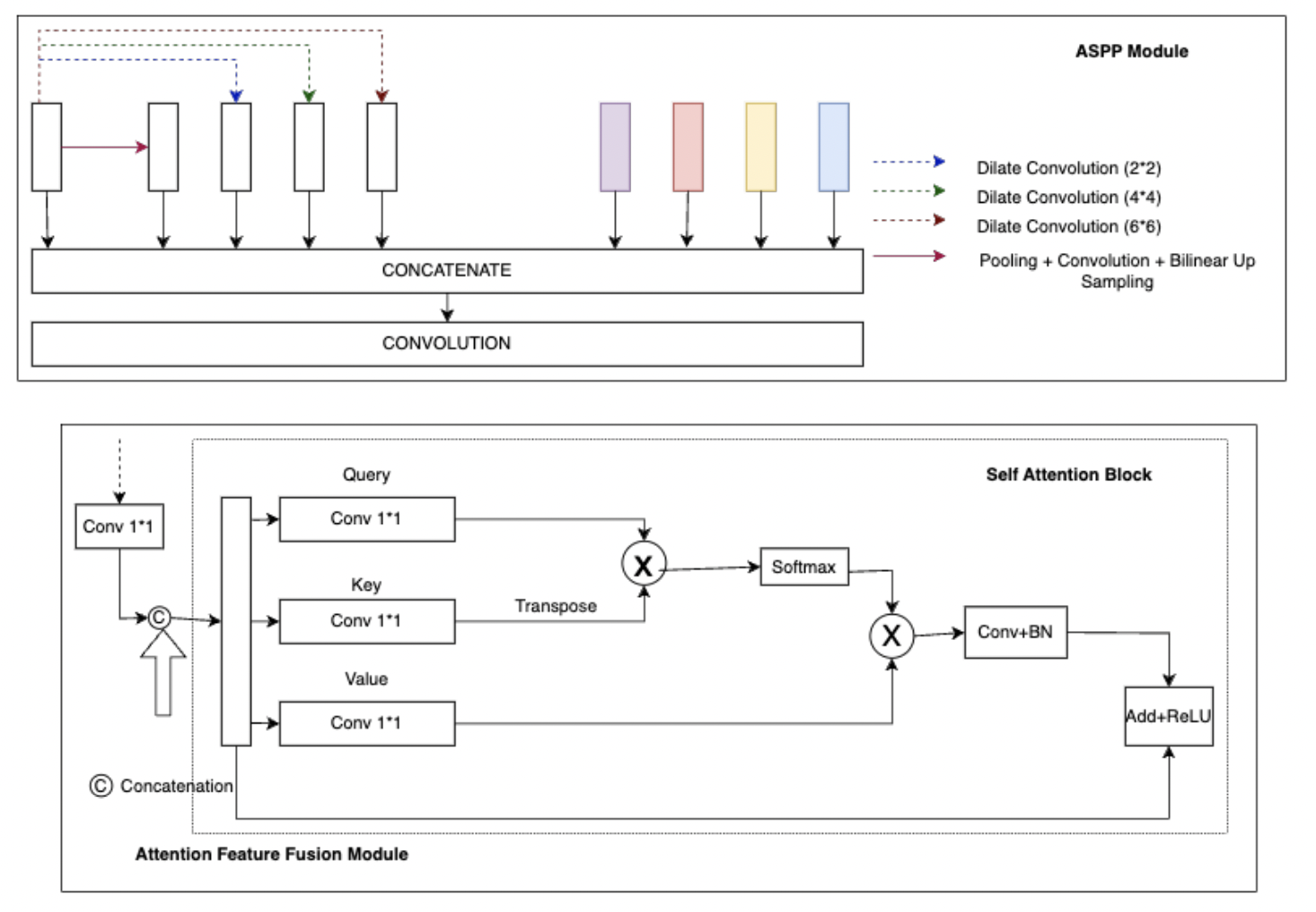
- Loss Function The model uses a combination of binary cross-entropy and Dice loss to handle the imbalanced nature of the dataset. Dice loss focuses on the boundary regions between cracks and non-crack areas, improving the segmentation performance of smaller cracks.
Experiments and Results
Dataset:
The model was trained and evaluated on a road crack image dataset consisting of thousands of images captured under varying lighting conditions, backgrounds, and noise levels. The dataset was split into training, validation, and test sets, with a focus on ensuring diverse coverage of crack patterns and conditions.Baseline Models:
A baseline ResNet model was used for comparison, with max-pooling layers for downsampling and no wavelet transform or attention mechanism. The ResNet model achieved a Test F1-score of 0.78.Loss:
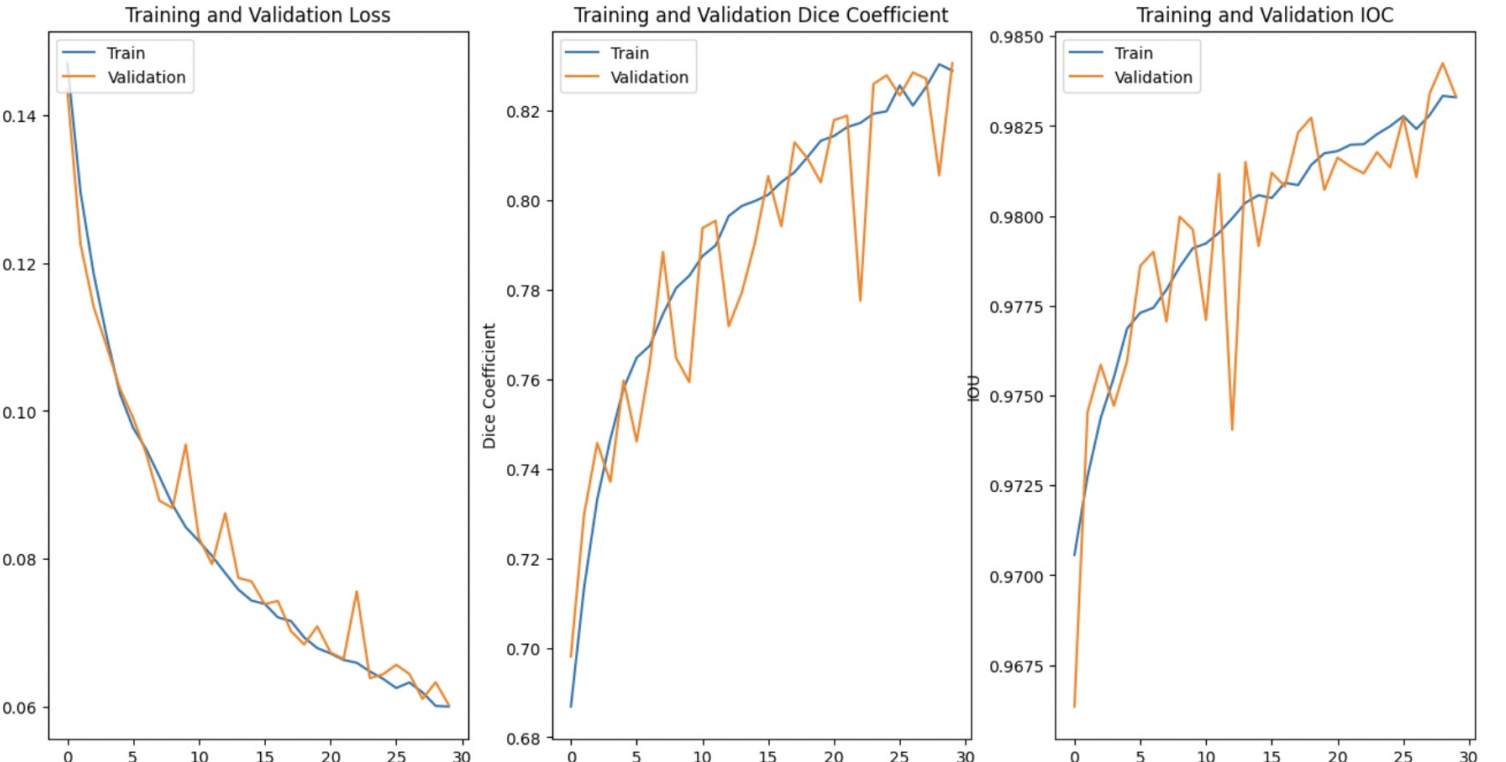
Performance of WUNet:
The proposed WUNet model achieved a Test F1-score of 0.82, representing a 0.4 improvement over the baseline ResNet model. The inclusion of DWT and IWT significantly improved the model’s ability to detect fine cracks and preserve texture information, while the self-attention mechanism helped in handling noisy backgrounds and complex crack patterns.
| Model | F1-Score |
| ResNet | 0.78 |
| WUNet | 0.82 |
- Qualitative Results:
Qualitative analysis showed that the WUNet model was able to detect cracks with higher precision and recall compared to the baseline. The model performed particularly well in detecting small and subtle cracks that were missed by ResNet. Below shows comparison of masks predicted by model and ground truth
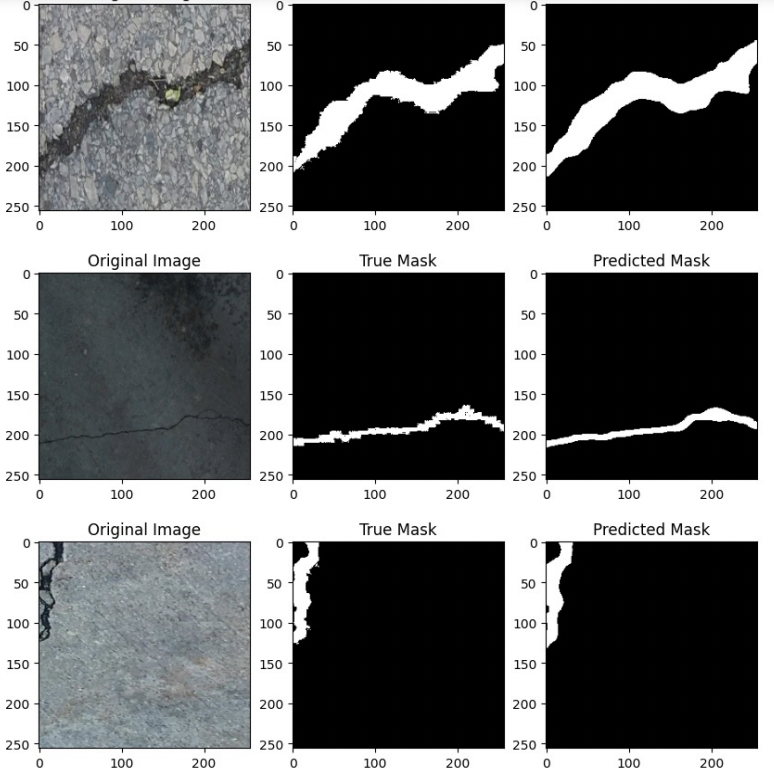
Conclusion
In this project, we proposed a novel Wavelet U-Net (WUNet) architecture for road crack detection. By replacing traditional pooling operations with Discrete Wavelet Transformation (DWT) and incorporating a self-attention mechanism, the model was able to preserve important texture information and capture both local and global context more effectively. The WUNet model outperformed a standard ResNet model, achieving a 0.4 increase in F1-score, demonstrating its effectiveness in automatic road crack detection.
Future work could explore integrating more advanced attention mechanisms and applying this approach to other infrastructure-related tasks such as bridge crack detection or pavement condition monitoring.
Read more in the Report